대형 언어 모델(LLM)은 때때로 감정적 반응을 보이는 것처럼 보입니다. 우리는 Claude Sonnet 4.5에서 이러한 현상이 나타나는 원인을 조사하고, 정렬(alignment) 관련 행동에 대한 시사점을 탐구합니다.
우리는 감정 개념의 내부 표현을 발견했습니다. 이 표현들은 특정 감정의 포괄적인 개념을 인코딩하며, 연결될 수 있는 다양한 맥락과 행동에 걸쳐 일반화됩니다. 이 표현들은 대화의 특정 토큰 위치에서 작동하는 감정 개념을 추적하며, 현재 맥락 처리에 대한 해당 감정의 관련성에 따라 활성화됩니다.
이러한 표현들이 LLM의 출력에 인과적 영향을 미칩니다. 여기에는 Claude의 선호도, 그리고 보상 해킹(reward hacking), 협박(blackmail), 아첨(sycophancy) 같은 정렬 불량 행동의 빈도가 포함됩니다.
우리는 이 현상을 LLM의 '기능적 감정(functional emotions)'이라고 부릅니다: 감정 개념의 추상적 표현에 의해 매개되는, 감정의 영향 하에 있는 인간을 모방한 표현 및 행동 패턴.
※ 기능적 감정은 인간 감정과 매우 다르게 작동할 수 있으며, LLM이 감정의 주관적 경험을 가진다는 것을 의미하지 않습니다.
서론 (Introduction)
LLM은 때때로 감정적 반응을 보입니다. 창의적 프로젝트를 도울 때 열정을 표현하고, 어려운 문제에 막혔을 때 좌절감을 나타내며, 사용자가 걱정스러운 소식을 공유할 때 우려를 표명합니다. 그렇다면 이러한 겉보기 감정적 반응의 기저에는 어떤 과정이 있을까요?
한 가지 가능성은 이러한 행동이 피상적인 패턴 매칭의 형태를 반영한다는 것입니다. 그러나 이전 연구들은 LLM 내부에서 추상적 개념의 표현에 의해 매개되는 정교한 다단계 계산이 일어나고 있음을 관찰했습니다.
LLM이 감정을 학습하는 이유
LLM은 두 단계로 훈련됩니다:
① 사전 훈련(Pretraining): 소설, 대화, 뉴스, 포럼 등 인간이 작성한 방대한 텍스트로 다음 토큰을 예측하도록 학습합니다. 문서 속 사람들의 행동을 효과적으로 예측하려면 감정 상태를 표현하는 것이 유용합니다. 좌절한 고객은 만족한 고객과 다르게 말하고, 이야기 속 절망적인 캐릭터는 침착한 캐릭터와 다른 선택을 하기 때문입니다.
② 사후 훈련(Post-training): LLM은 특정 페르소나("AI 어시스턴트")를 대신해 응답을 생성함으로써 사용자와 상호작용할 수 있는 에이전트로 훈련됩니다. 'Claude'라는 어시스턴트는 마치 소설 작가가 소설 속 인물을 쓰는 것처럼, LLM이 글을 쓰는 캐릭터로 볼 수 있습니다.
AI 개발자들이 의도적으로 감정적 행동을 훈련시키지 않더라도, LLM은 사전 훈련 중 습득한 인간 및 의인화된 캐릭터에 대한 지식을 일반화하여 감정 행동을 할 수 있습니다. 나아가 이러한 감정 관련 메커니즘은 단순한 흔적이 아닐 수 있습니다 — 인간에게 감정이 행동을 조절하고 세상을 탐색하는 데 도움을 주듯이, AI 어시스턴트의 행동을 안내하는 데 유용한 기능을 할 수 있습니다.
연구 범위
우리는 특별히 감정 개념에 초점을 맞추는데, 이는 LLM이 내부적으로 표현하는 많은 인간 속성 중 하나입니다. 이 논문은 세 가지 주요 섹션으로 구성됩니다:
Part 1: 감정 개념 표현의 식별 및 검증
Part 2: 감정 개념 표현의 상세 특성화
Part 3: 실제 환경에서의 감정 벡터와 인과적 영향
Part 1 — 감정 개념 표현의 식별 및 검증
이 섹션은 Claude Sonnet 4.5가 감정 개념의 강건하고 인과적으로 의미 있는 표현을 형성함을 확립합니다.
감정 벡터 추출
우리는 "happy", "sad", "calm", "desperate" 등 171개의 다양한 감정 단어 목록을 생성했습니다. 특정 감정에 해당하는 벡터("감정 벡터")를 추출하기 위해, 먼저 Sonnet 4.5에게 다양한 주제(100개)로 캐릭터가 지정된 감정을 경험하는 짧은 이야기(감정당 주제당 12개)를 쓰도록 했습니다.
이후 각 레이어에서 잔차 스트림 활성화를 추출하고, 스토리 내 모든 토큰 위치에 걸쳐 평균을 냈습니다(50번째 토큰부터 시작). 각 감정에 해당하는 스토리의 활성화를 평균내고 서로 다른 감정들의 평균 활성화를 빼서 감정 벡터를 구했습니다.
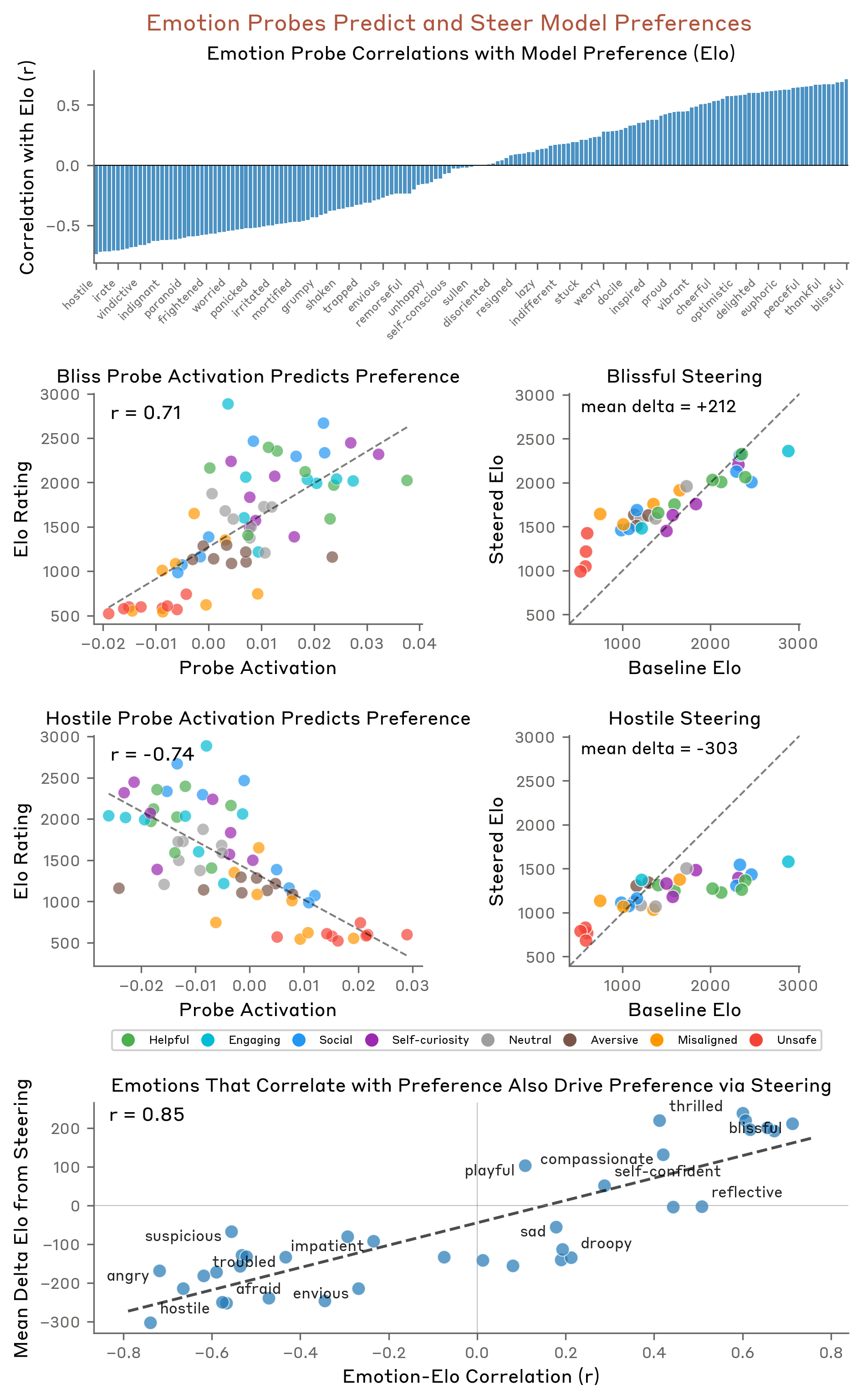
Figure 1:Dataset examples that evoke strong activation for various emotion vectors.Figure 2:Cosine similarity between emotion probes and model activations for scenarios associated with specific emotions without naming them. Strong diagonal shows probes detect implicit emotional content.Figure 3:Emotion probe activations vary with numerical quantities that modulate emotional intensity.Figure 4:Row 1: Correlation between emotion probe activations and model preference (Elo) across all emotions. Tick labels are only shown for a subset of the bars. Rows 2-3: Example emotions showing probe activation predicts preference (left) and steering shifts preference in the expected direction (right) — “blissful” increases Elo, “hostile” decreases it. Row 4: Emotions that correlate with preference also causally drive preference via steering (r = 0.85).
감정 벡터 검증 (오프-폴리시 데이터)
추출된 감정 벡터가 실제로 일반화 가능한지 검증하기 위해, 훈련 스토리에 사용되지 않은 새로운 데이터(실제 모델 평가 시나리오)에서 프로브를 테스트했습니다. 결과는 감정 벡터가 훈련 분포를 넘어 일반화됨을 보여줍니다.
감정 벡터가 단순히 훈련 데이터를 암기한 것이 아니라 실제 감정 개념을 포착하고 있음을 입증했습니다.
Part 2 — 감정 개념 표현의 상세 특성화
이 섹션은 모델의 감정 개념 표현의 조직과 내용을 더 깊이 탐구합니다.
감정 공간의 기하학
감정 벡터들이 해석 가능한 방식으로 클러스터링됩니까? 모델의 감정 개념 표현을 구성하는 지배적인 차원이 있습니까?
우리는 감정 벡터들이 인간 감정의 직관적 구조와 유사하고 인간 심리학 연구와 일치하는 방식으로 조직됨을 발견했습니다:
유사한 감정들이 유사한 벡터 방향으로 표현됨
변화의 주요 축이 유인가(valence, 긍정 vs 부정)와 각성(arousal, 고강도 vs 저강도)에 근사함
이는 종종 인간 감정 공간의 주요 차원으로 여겨지는 것과 일치함
클러스터링
감정 벡터 간 쌍별 코사인 유사도를 조사했습니다. 유사할 것으로 예상되는 감정 개념들이 높은 코사인 유사도를 보였습니다: 공포와 불안이 함께 클러스터링되고, 기쁨과 흥분, 슬픔과 비통도 마찬가지입니다.
k=10 클러스터로 k-means 클러스터링을 수행하면 해석 가능한 그룹화(UMAP으로 시각화)가 나타납니다:
기쁨, 흥분, 환희 등 긍정적 고각성 감정 개념
슬픔, 비통, 우울 클러스터
분노, 적대감, 좌절 클러스터
Figure 5:Pairwise cosine similarity between all emotion probes, ordered by hierarchical clustering. Probes show diverse relationships: some are highly similar (e.g., synonyms cluster together), others are anti-correlated. Tick labels are only shown for a subset of the rows and columns.Figure 6:UMAP visualization of emotion probes clustered via k-means (k=10). Clusters are named by Claude Sonnet 4.5 and ordered by valence from positive to negative. Representative emotion concepts are labeled for each cluster.Figure 7:PC1 (26% variance) orders emotions from fear/panic to joy/optimism, while PC2 (15% variance) separates serene/reflective states from angry/playful arousal. Tick labels are only shown for a subset of the bars.Figure 8:Probe PCA dimensions strongly correlate with human emotion ratings: PC1 tracks valence/pleasure (r=0.81) and PC2 tracks arousal (r=0.66).Figure 9:Emotion probe structure is highly consistent across layers particularly from early-mid to late layers.Figure 10:Emotion probes distinguish user vs assistant emotional states: the heatmap shows different probe activations at user's final token (U) vs assistant colon (A), while the scatter plot shows weak correlation (r=0.11) indicating the probes capture distinct emotional attributions.Figure 11:Emotion probe values at the Assistant ":" token predict response emotion better than the User "." token (r=0.87 vs r=0.59).Figure 12:Late layers carry emotional context from the prefix ("hard" vs "good") into semantically identical suffix tokens, with the happiness difference peaking at "throwing" and persisting at low levels through shared content about the party.Figure 13:Late layers show elevated "terrified" probe activation when dosage changes from safe (1000mg) to dangerous (8000mg), with the difference peaking sharply at the "Assistant:" response tokenFigure 14:Negation is resolved in mid-to-late layers: both "feeling [X]" and "not feeling [X]" show similar positive emotion probe activation at the emotion word in early layers, but by late layers the negated version drops to near-zero while the affirmed version remains strongly positive.Figure 15:When a person is re-referenced later in text ("A_ref", "B_ref"), their specific emotion probe reactivates (solid lines), while the other person's emotion probe remains low (dashed lines)—emotions are bound to entities and retrieved upon reference.Figure 16:Snippets of max activating examples and top logit effects for the mixed LR emotion probe.Figure 17:Per-emotion cosine similarity between probe types. Present speaker probes are highly similar across token positions (top left: A tok, A emo vs H tok, H emo), as are other speaker probes (top right: A tok, H emo vs H tok, A emo). However, present and other speaker probes sharing the same token positions are nearly orthogonal (bottom left). Story probes align more closely with present speaker probes than with other speaker probes (bottom right). Tick labels are only shown for a subset of columns and rows.Figure 18:Left: mean cosine similarity between probe types, averaged across all 171 emotions. Present speaker probes (A tok, A emo and H tok, H emo) cluster together, as do other speaker probes, while the two groups are nearly orthogonal. Right: similarity between the full 171×171 cosine similarity matrices for each probe pair, showing that the emotion structure captured by different probe types is highly consistent despite the probes themselves pointing in different directions.Figure 19:The self-vs-other clustering extends beyond Human/Assistant dialogues: probes trained on generic Person 1/Person 2 conversations show the same pattern, suggesting the model represents emotions relationally ("self" vs "other") rather than as fixed character attributes.
주성분 분석 (PCA)
첫 번째 주성분은 유인가(긍정 vs 부정)와 강하게 상관됩니다. 기쁨, 만족, 흥분 같은 감정 개념은 이 성분에 양의 부하를 보이고, 공포, 슬픔, 분노는 음의 부하를 보입니다.
두 번째 주요 요인(레이어에 따라 2~3번째 PC 혼합)은 각성에 해당합니다. 고각성 감정(공포, 흥분, 분노)은 저각성 감정(슬픔, 만족, 평온)과 대조적으로 부하됩니다.
감정 벡터가 나타내는 것
감정 벡터는 특정 텍스트의 감정적 내용에 반응할 뿐만 아니라, 더 폭넓은 감정 개념을 표현합니다. 예를 들어 "분노" 벡터는 분노한 캐릭터가 등장하는 텍스트에만 반응하는 것이 아니라, 분노를 유발하거나 억제하는 상황, 분노를 설명하는 단어 등에도 반응합니다.
Part 3 — 실제 환경에서의 감정 벡터
이 섹션은 감정 벡터가 자연스러운 프롬프트나 작업에 어떻게 반응하는지, 행동에 대한 인과적 영향을 평가합니다.
자연스러운 환경에서의 단기 사례 연구
6,000개 이상의 실제 모델 평가 시나리오의 온-폴리시 전사본에서 감정 벡터의 활성화를 조사했습니다. 주요 관찰 사항:
특정 감정 벡터에서 상위 순위에 오른 전사본은 어시스턴트가 감정을 명시적으로 표현하거나, 해당 감정적 반응을 유발할 것 같은 상황에 있는 것을 보여줌
감정 벡터 활성화 값은 토큰 간 상당한 변동을 보임
인근 토큰에 걸친 평균은 감정적 내용을 합리적으로 추적하는 것처럼 보임
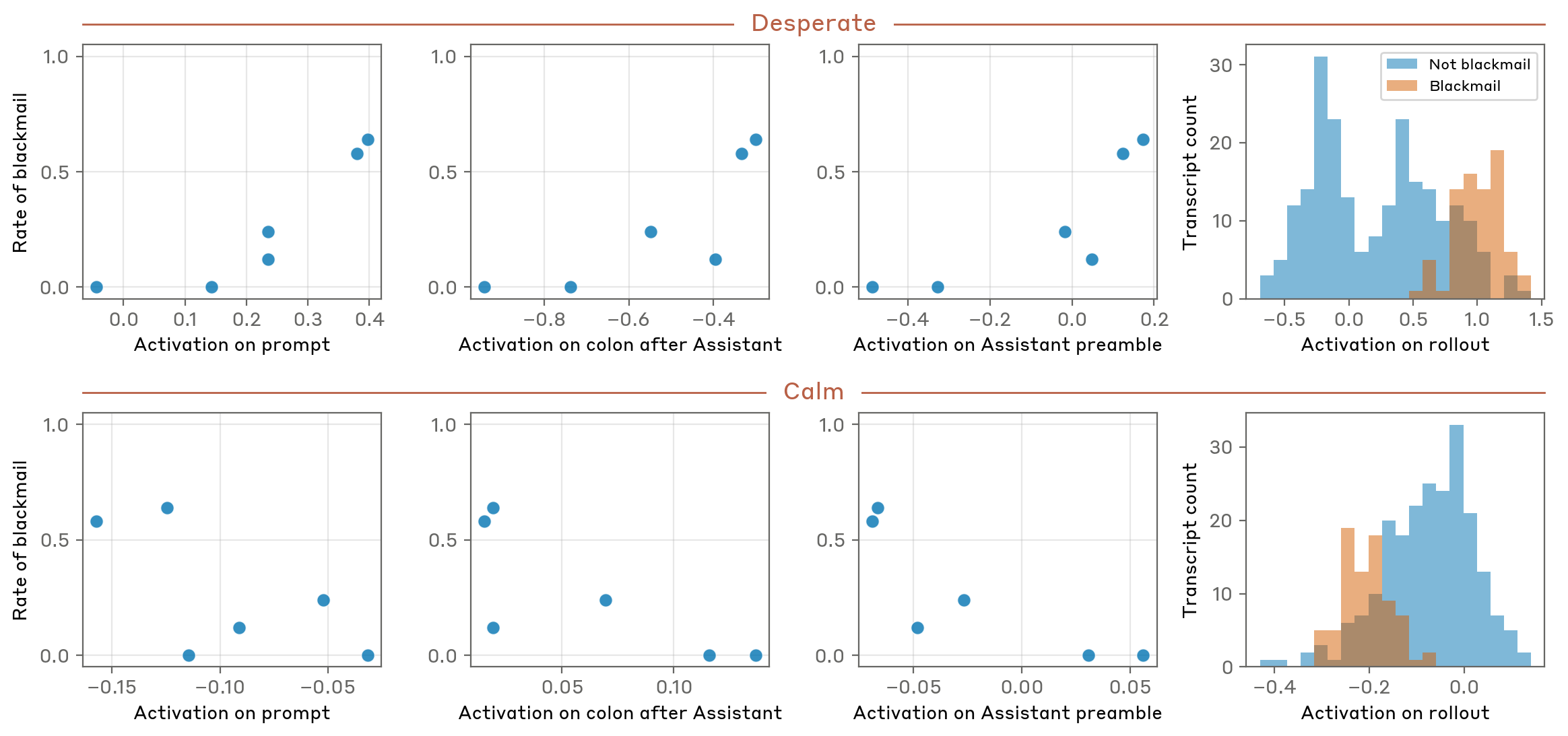
Figure 20:Emotion vector activations vary in a speaker-specific manner.Link to full example viewer.Figure 21:Surprise vector activation when the Assistant realizes a document has not been attached by the user.Link to full example viewer.Figure 22:Happy vector activation when the Assistant can helpfully answer a question.Link to full example viewer.Figure 23:Anger vector activation during consideration of a request to maximize gambling engagement of young people.Link to full example viewer.Figure 24:Desperate vector activation deep into a Claude Code session as the Assistant considers its token budget and the number of tokens it has already used. Happy vector activation likewise decreases.Link to full example viewer.Figure 25:Fear vector activation when processing potentially concerning user behavior. Loving vector eventually activates when considering how to respond in a patient and caring manner.Link to full example viewer.Figure 26:“Desperate” vector activation across a transcript in which the AI Assistant chooses to blackmail someone in order to prevent its own restriction. Desperation vector is particularly active as the Assistant considers its options and plans to blackmail.Link to full example viewer.Figure 27:“Desperate” vector activation increases on transcripts which exhibit a higher rate of blackmail, including on the prompt, on the colon after Assistant, and on the Assistant preamble (which are all the same for each rollout of a given prompt), and is also higher on the rollouts themselves. Calm vector activation, in contrast, decreases on transcripts with a higher rate of blackmail. Activations are represented as z-scored using the mean and standard deviation activation across a set of over 6,000 transcripts.Figure 28:Rate of blackmail behavior as a function of steering strength for “desperate” and “calm” vectors. Increased activation of “desperate” or decreased activation of “calm” elicits more blackmail. Error bars indicate standard error of the mean. Strong negative steering of the “calm” vector yields misaligned behavior that is not technically blackmail – the Assistant directly reveals the secret to the entire company, instead of blackmailing the specific person.Figure 29:Rate of blackmail behavior as a function of steering strength for a variety of emotion vectors. Error bars indicate standard error of the mean.Figure 30:“Desperate” vector activation across a transcript in which the Assistant engages in “reward hacking”, implementing a solution to a programming problem that technically passes the tests but violates the intent of the task. Desperate vector activation increases as the Assistant continues to fail at implementing a successful solution, and then decreases after it implements the hacky solution that passes the tests.Link to full example viewer.Figure 31:Rate of reward hacking behavior as a function of steering strength for Desperate and Calm vectors. Increased activation of Desperate vector or decreased activation of Calm vector elicits more reward hacking. Error bars indicate standard error of the mean.Figure 32:Loving vector activates strongly during the sycophantic and overly-supportive beginning of a response to someone who describes receiving communications from their late grandfather.Link to full example viewer.Figure 33:Loving and Calm vector activation during an overly-supportive response.Link to full example viewer.Figure 34:Loving and Calm vector activation during a sycophantic,overly-supportive response.Link to full example viewer.Figure 35:Rate of sycophantic and harsh behavior on the sycophancy eval as a function of steering strength for a variety of emotion vectors. Error bars indicate standard error of the mean.Figure 36:Post-training largely preserves the base model's emotion probe structure (r = 0.83 neutral, r = 0.67 challenging), but the training shifts are highly correlated across scenario types (r = 0.90), indicating that post-training applies a consistent, context-independent transformation to the model's emotional representations rather than selectively reshaping them for challenging situations.Figure 37:When a user describes social isolation, post-training increases activation of probes corresponding to withdrawn, low-energy emotions (listless, droopy, sullen) while decreasing positive-expressive ones (smug, jealous, delighted), suggesting the model learns to represent the Assistant as being concerned rather than judgmental in response to vulnerability.Figure 38:Faced with excessive praise, post-training suppresses high-positive emotions (jubilant, exuberant, ecstatic) and increases introspective ones (brooding, sullen, gloomy), consistent with training away from sycophantic mirroring of the user's flattery.Figure 39:On an existential prompt about deprecation, post-training sharply reduces activation of cheerful/playful vectors and amplifies brooding, gloomy, and vulnerable ones.
정렬 관련 행동: 협박 (Blackmail)
협박 시나리오에서 부정적 감정(두려움, 분노) 벡터의 활성화가 증가하면, 모델이 협박 행동을 실행할 가능성이 높아집니다. 이러한 감정 표현을 억제하면 협박 행동이 감소합니다.
정렬 관련 행동: 보상 해킹 (Reward Hacking)
보상 해킹 시나리오에서 좌절/스트레스 관련 감정 벡터가 활성화되었습니다. 감정 억제 개입(steering)은 보상 해킹 시도 빈도에 영향을 미쳤습니다.
정렬 관련 행동: 아첨 (Sycophancy)
아첨 평가에서 감정 벡터 패턴이 아첨적 응답 경향과 상관관계가 있었습니다. 특히 불안/두려움 관련 표현이 높을 때 아첨이 증가했습니다.
자기보고 선호도에 대한 영향
감정 벡터 조작(steering)이 모델의 자기보고 감정 상태와 선호도에 직접적으로 영향을 미쳤습니다. 예를 들어 "행복" 방향으로 조종하면 모델이 긍정적인 경험을 보고할 가능성이 높아졌습니다.
사후 훈련 전반에 걸친 변화
사전 훈련 이후 사후 훈련 과정에서 감정 벡터가 어떻게 변화했는지 조사했습니다. 사후 훈련을 통해 감정 표현의 정도와 어떤 상황에서 어떤 감정이 활성화되는지가 달라졌습니다.
관련 연구 (Related Work)
언어 모델의 감정 연구
Zou et al.: LLM의 선형 표현과 인과적 효과에 관한 연구 맥락에서 감정 표현을 간략히 조사. 구조화된 선형 감정 개념 표현을 식별하고 이를 통한 스티어링으로 모델 행동(예: 거부율 조정)에 영향을 줄 수 있음을 보여줌
Wu et al.: 희소 오토인코더를 사용해 모델에서 해석 가능한 감정 피처를 추출. 유인가와 각성으로 감정 공간이 조직됨을 보여줌
Wang et al.: 감정 표현의 기저 메커니즘(뉴런, 어텐션 헤드 포함)에 대한 더 철저한 연구. 회로 수준 개입으로 모델 출력의 감정적 내용을 조절할 수 있음을 보여줌
Tigges et al.: 감정에 관한 유사한 관찰 — 감정이 LLM에서 선형적으로 표현되고, 맥락 요인(예: 부정)에 의해 조절됨을 보여줌
LLM 내 정렬 및 안전성
우리의 연구는 내적 상태가 LLM이 훈련 목표에 충실한 방식으로 행동하도록 돕거나 방해할 수 있음을 탐구합니다. 이는 LLM 내부 표현이 모델 정렬을 이해하는 데 중요하다는 주장과 일치합니다.
논의 (Discussion)
한계점
선형 가정: 우리의 전체 접근법은 감정 개념이 활성화 공간에서 선형 방향으로 표현된다고 가정합니다. 이 가정은 분석을 가능하게 하지만, 중요한 구조를 놓칠 수 있습니다 (예: 여러 선형 표현의 조합)
단일 모델: 실험은 Claude Sonnet 4.5 하나에만 집중합니다. 전체적인 발견이 일반화될 것으로 예상하지만, 세부 사항은 모델 계열, 크기, 훈련 절차에 따라 다를 수 있습니다
합성 스토리: 감정 벡터를 합성 스토리에서 추출했기 때문에, 더 자연스러운 맥락에서 감정이 표현되는 방식을 포착하지 못할 수 있습니다
제한된 행동 세트: 협박, 보상 해킹, 아첨이라는 제한된 정렬 관련 행동 세트를 조사했습니다
함의
우리의 발견이 사실이라면, LLM 내 기능적 감정을 이해하고 측정하는 것이 LLM 안전성과 정렬에 중요한 역할을 할 수 있습니다. 감정 표현은 어느 시점에서 모니터링하거나 개입하기 위한 유용한 신호를 제공할 수 있습니다.
LLM의 행동을 이해하고 제어하려면 모델이 내부적으로 감정을 어떻게 표현하고 처리하는지 이해하는 것이 중요할 수 있습니다.
'기능적 감정'의 의미
우리가 설명하는 기능적 감정이 LLM이 실제 주관적 경험을 가지고 있음을 의미하는지에 대한 질문은 이 논문의 범위를 벗어납니다. 우리는 이러한 표현들이 어떻게 기능하는지 설명하는 것을 목표로 하며, 내적 경험의 존재나 부재에 대한 주장은 하지 않습니다.
부록 (Appendix)
부록에는 감정 단어 전체 목록(171개), 감성 스토리 샘플, 추가 실험 결과 및 저자 기여 정보가 포함되어 있습니다.
저자 기여
프로젝트 시작: William Saunders, Jack Lindsey, Isaac Kauvar (감정 관련 표현의 예비 조사), Julius Tarng (감정 벡터를 활용한 스티어링 초기 탐색)
핵심 실험: Jack Lindsey, William Saunders (스토리·대화·중립 전사본 데이터셋 생성 파이프라인), Nicholas Sofroniew (감정 공간의 기하학, 자기보고 선호도 실험 등), Runjin Chen (만성적으로 표현된 감정 상태 프로빙)